Mean Shift for Self-Supervised Learning
1University of Maryland, Baltimore County, 2University of California, Davis
∗ denote equal contribution

Abstract
Most recent self-supervised learning (SSL) algorithms learn features by contrasting between instances of images or by clustering the images and then contrasting between the image clusters. We introduce a simple mean-shift algorithm that learns representations by grouping images together without contrasting between them or adopting much of prior on the structure of the clusters. We simply "shift" the embedding of each image to be close to the "mean" of its neighbors. Since in our setting, the closest neighbor is always another augmentation of the same image, our model will be identical to BYOL when using only one nearest neighbor instead of 5 as used in our experiments. Our model achieves 72.4% on ImageNet linear evaluation with ResNet50 at 200 epochs outperforming BYOL.
Contributions
We introduce a simple but effective mean-shift algorithm to group similar images together in the neighborhood of each image in an online fashion. The idea is to simply find the nearest neighbors of a query image in the embedding space and pull the embedding of query to be closer to the center of those neighbors. We believe this process will result in developing clusters of images in the embedding space without enforcing much constraints about their specific size, number, or shape. Note that in contrast to grouping (pulling) in our method, MoCo pushes the query to be far from any other data points particularly nearest neighbors by which the loss will be dominated.
For two random query images, we show how the nearest neighbors evolve at the learning time. Initially, NNs are not semantically quite related, but are close in low-level features. The accuracy of 1-NN classifier in the initialization is 1.5% which is 15 times larger than random chance (0.01%). This little signal is bootstrapped in our learning method and results in NNs of the late epochs which are mostly semantically related to the query image.

Method
Similar to BYOL, we maintain two encoders ("target" and "online") using momentum update for the target encoder. We augment an image twice and feed to both encoders. We add the target embedding to the memory bank and look for its nearest neighbors in the memory bank. Obviously target embedding itself will be the first nearest neighbor. We want to shift the query image towards the mean of target's nearest neighbors, so we minimize the summation of those distances. Note that our method using only one nearest neighbor is identical to BYOL which pulls different augmentations together without grouping different instances of images. To our knowledge, our method is the first in grouping different instances of images without contrasting between image instances or clusters.
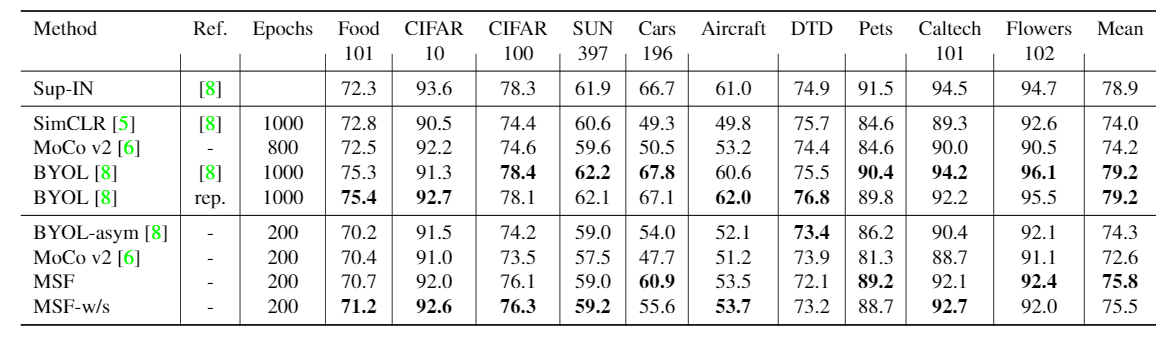
Self-supervised Learning Results
We compare our model on the full ImageNet linear and nearest neighbor benchmarks using ResNet50. We find that given similar computational budget, our models are better than other state-of-the-art methods. Our w/s variation works slightly better than the regular MSF. Note that methods with symmetric loss are not directly comparable with the other ones as they need to feed each image twice though each encoder. This results in twice the computation for each mini-batch. One may argue that a non-symmetric BYOL with 200 epochs should be compared with symmetric BYOL with 100 epochs only as they use similar amount of computation. Note that symmetric MoCo v2 with 400 epochs is almost the same as asymmetric MoCo v2 with 800 epochs (71.0 vs. 71.1).
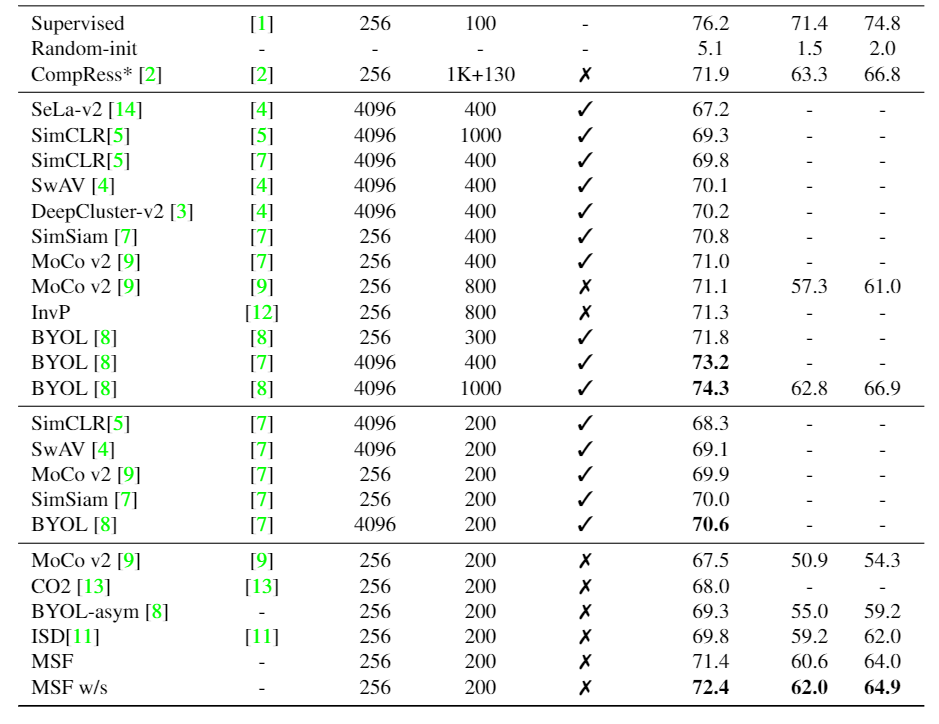
We compare our model on the ImageNet 1% and 10% linear evaluation benchmarks for ResNet50. The column "Fine-tuned" refers to whether the full network was fine-tuned or a single linear layer was trained. Given similar computational budgets, both of our models are better than other state-of-the-art methods.
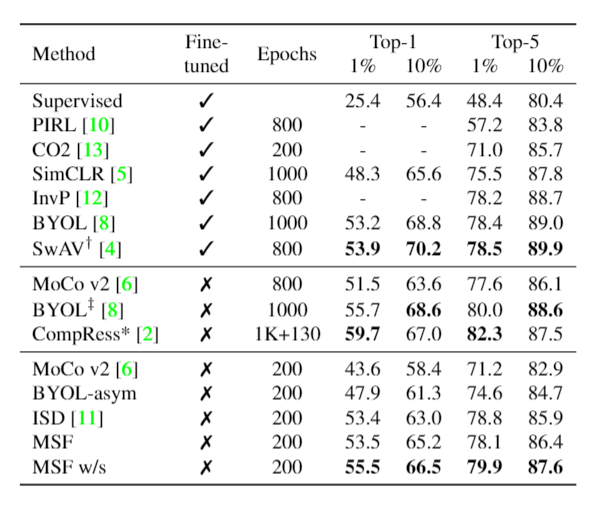
We compare various SSL methods on transfer tasks by training linear layers. Under similar computational budgets, we show that our models are consistently better or on par with other state-of-the-art methods. Only a single linear layer is trained on top of features. No train time augmentations are used. "rep." means we have reproduced the results using our evaluation framework for better comparison.
Evolution of Representation Over Training
We visualize the normalized features for 10 random ImageNet classes at certain epochs of MSF training. We find that over the period of training, semantic clusters are formed in the feature space.

Nearest Neighbors Over Training
For two random query images, we show how the nearest neighbors evolve at the learning time.

Cluster Visualizations
We cluster ImageNet dataset into 1000 clusters using k-means and show random samples from random clusters. Each row corresponds to a cluster. Note that semantically similar images are clustered together.

References
[1] Torchvision models.https://pytorch.org/docs/stable/torchvision/models.html.
[2] Soroush Abbasi Koohpayegani, Ajinkya Tejankar, and Hamed Pirsiavash. Compress: Self-supervised learning by compressing representations. Advances in Neural Information Processing Systems, 33, 2020.
[3] Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. Deep clustering for unsupervised learning of visual features. InProceedings of the European Conference on Computer Vision (ECCV), pages 132–149, 2018.
[4] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. In Advances in Neural Information Processing Systems, pages 9912–9924. Curran Associates, Inc., 2020.
[5] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020.
[6] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
[7] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. arXiv preprint arXiv:2011.10566,2020.
[8] Jean-Bastien Grill, Florian Strub, Florent Altche, Corentin Tallec, Pierre H Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv preprintarXiv:2006.07733, 2020.
[9] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020.
[10] Ishan Misra and Laurens van der Maaten. Self-supervised learning of pretext-invariant representations. arXiv preprint arXiv:1912.01991, 2019.
[11] Ajinkya Tejankar, Soroush Abbasi Koohpayegani, Vipin Pillai, Paolo Favaro, and Hamed Pirsiavash. ISD: Self-supervised learning by iterative similarity distillation, 2020.
[12] Feng Wang, Huaping Liu, Di Guo, and Sun Fuchun. Unsupervised representation learning by invariance propagation. In Advances in Neural Information Processing Systems, volume 33, pages 3510–3520. Curran Associates, Inc., 2020.
[13] Chen Wei, Huiyu Wang, Wei Shen, and Alan Yuille. Co2: Consistent contrast for unsupervised visual representation learning. arXiv preprint arXiv:2010.02217, 2020.
[14] Asano YM., Rupprecht C., and Vedaldi A. Self-labelling via simultaneous clustering and representation learning. In International Conference on Learning Representations, 2020.