CompRess:
Self-Supervised Learning by Compressing Representations
University of Maryland, Baltimore County
∗ denote equal contribution
Abstract
Self-supervised learning aims to learn good representations with unlabeled data. Recent works have shown that larger models benefit more from self-supervised learning than smaller models. As a result, the gap between supervised and self-supervised learning has been greatly reduced for larger models. In this work, instead of designing a new pseudo task for self-supervised learning, we develop a model compression method to compress an already learned, deep self-supervised model (teacher) to a smaller one (student). We train the student model so that it mimics the relative similarity between the datapoints in the teacher's embedding space. For AlexNet, our method outperforms all previous methods including the fully supervised model on ImageNet linear evaluation (59.0% compared to 56.5%) and on nearest neighbor evaluation (50.7% compared to 41.4%). To the best of our knowledge, this is the first time a self-supervised AlexNet has outperformed supervised one on ImageNet classification.
Contributions
The goal of self-supervised learning is to learn good representations without annotations. We find that recent improvements in self-supervised learning have significantly reduced the gap between them and supervised learning for higher capacity models. But, the gap is still huge for small and simpler models. Thus, we propose to learn representations by training a high capacity model using an off-the-shelf self supervised method. And then compressing it to a smaller model through a novel compression method. Using our framework(CompRess), we train the student using unlabeled ImageNet which is better than training a self-supervised model from the scratch. Our method reduce the gap between SOTA self-supervised and supervised models and even outperformed supervised model in Alexnet architecture.
Method
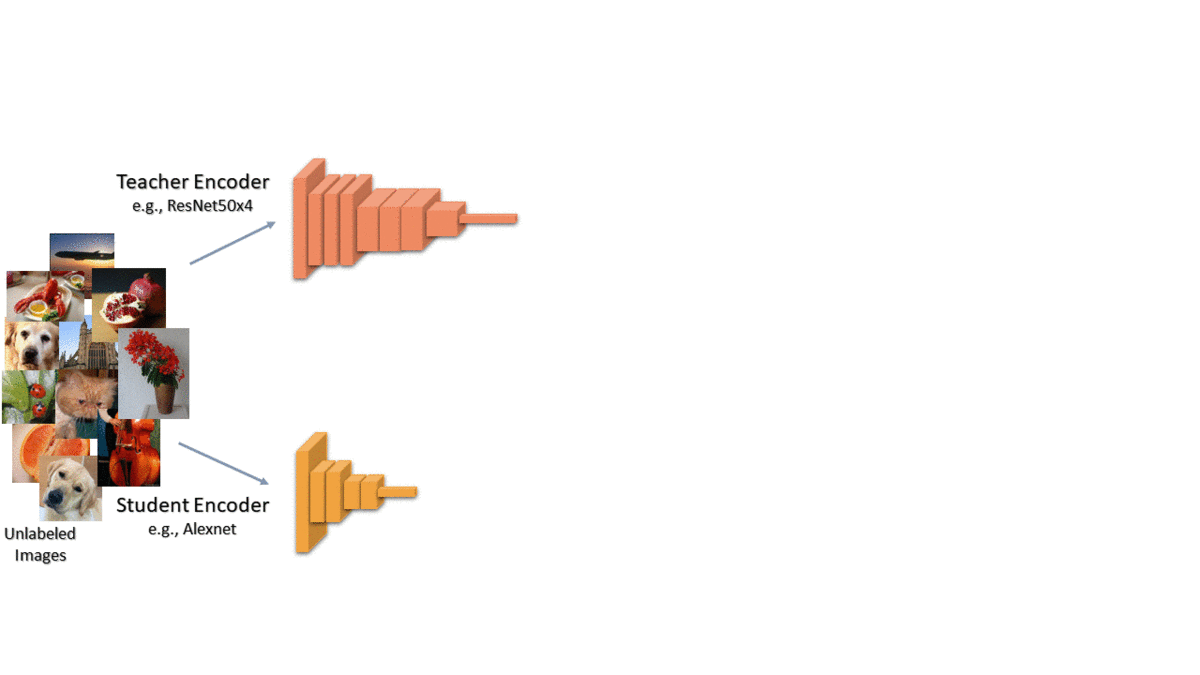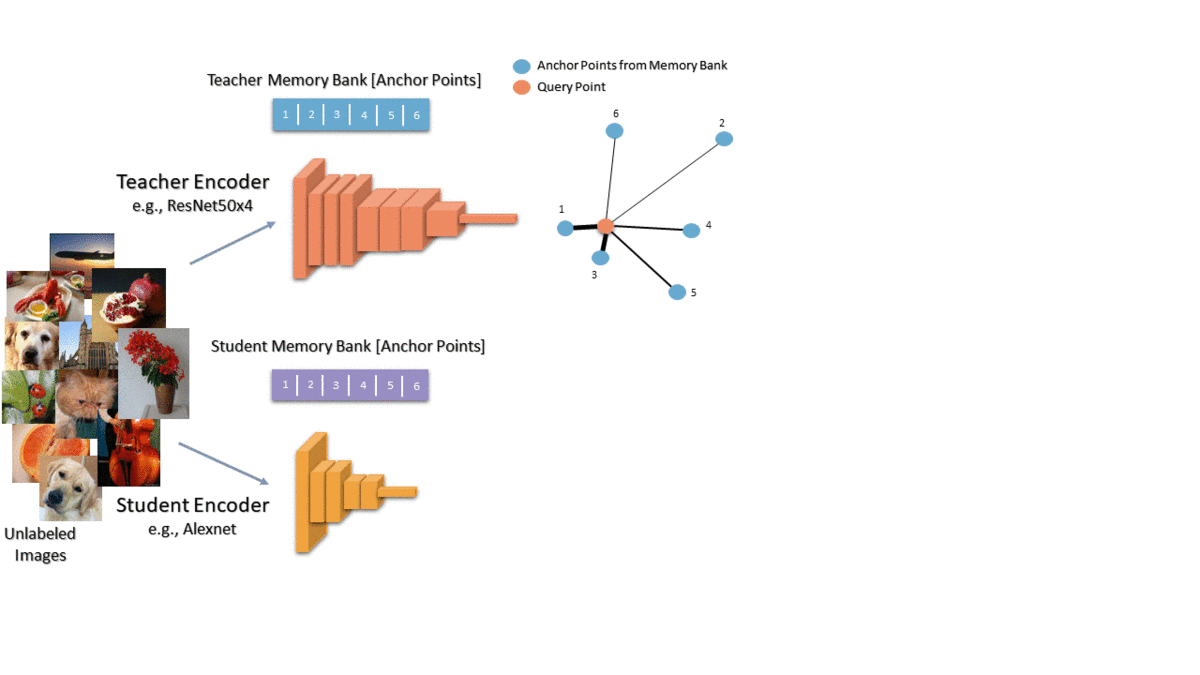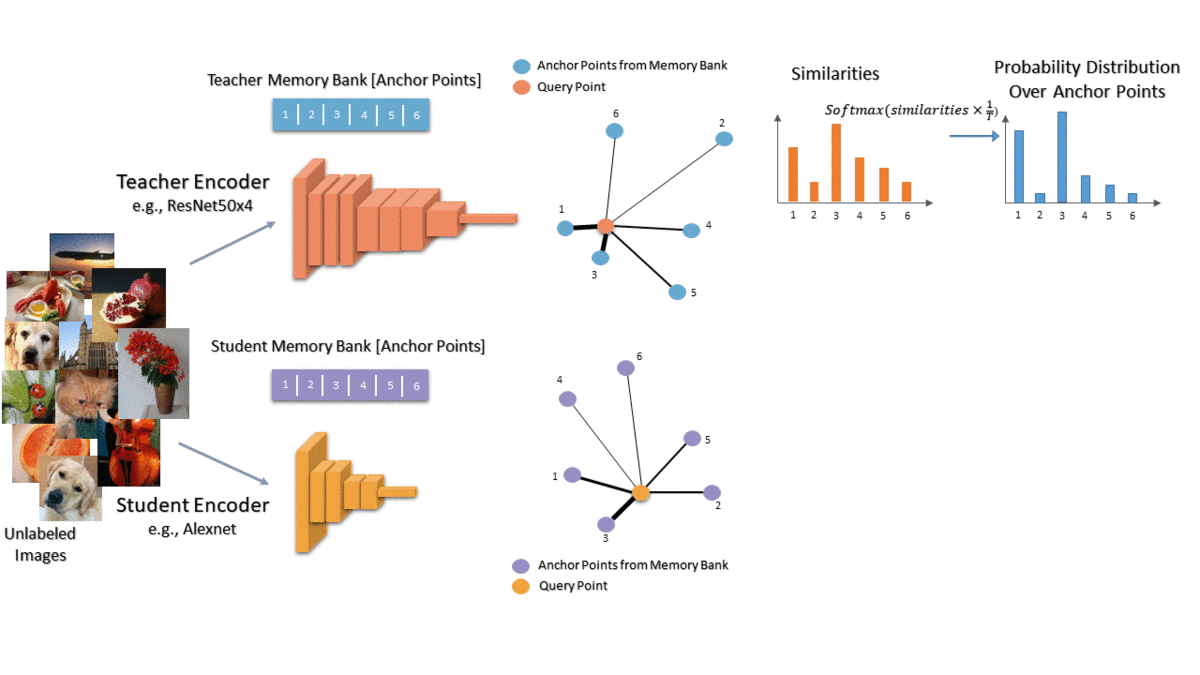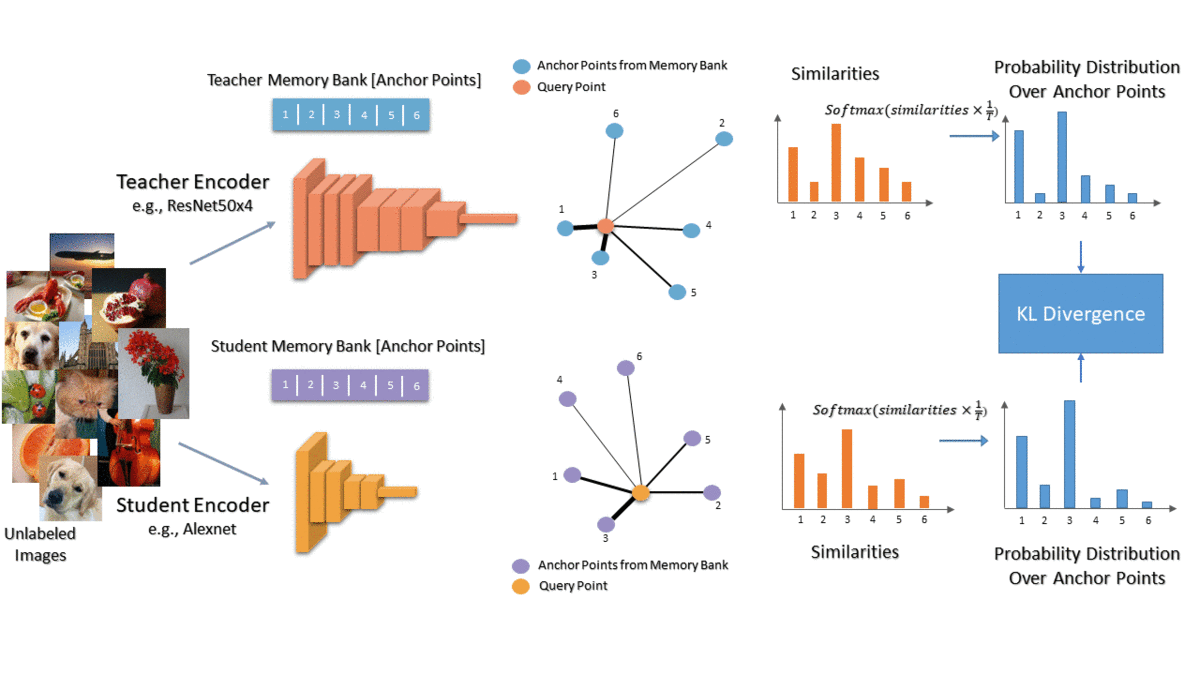
We propose to capture the similarity of each data point to the other training data in the teacher’s embedding space and then transfer that knowledge to the student. For each image, we compare it with a random set of anchor points and convert the similarities to a probability distribution over the anchor points. This distribution represents each image in terms of its nearest neighbors. We want to transfer this knowledge to the student so we get the same distribution for the student as well. Finally, we train the student to minimize the KL divergence between the two distributions. Intuitively, we want each data point to have the same neighbors in both teacher and student embeddings.
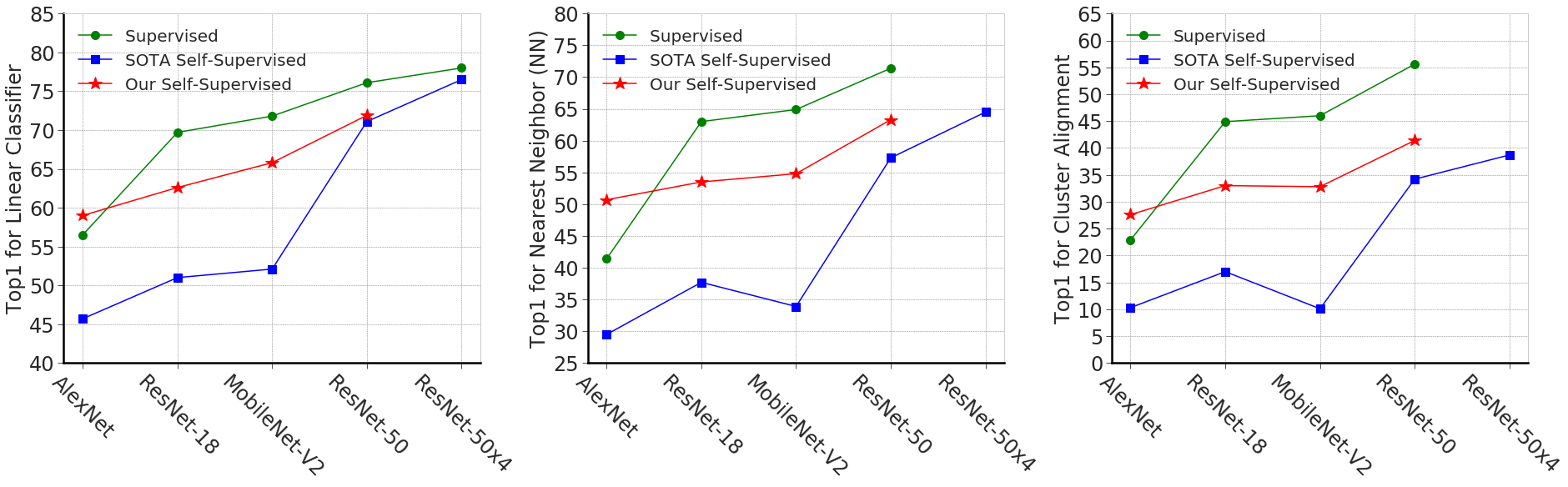
Results
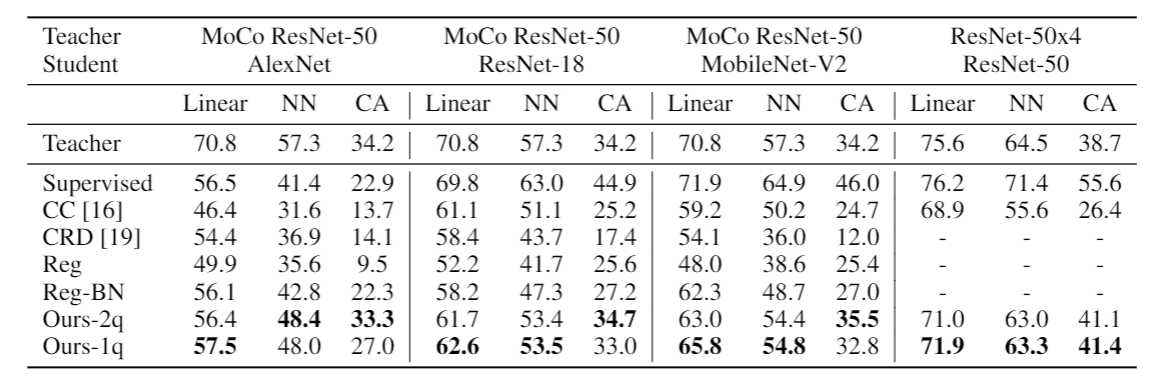
Looking at the results, we find that our method is better than other compression methods by a large margin across 3 different evaluation benchmarks and 2 different teacher SSL methods. This demonstrates the general applicability of our method. Inaddition, when we compress ResNet-50x4 to AlexNet, we get 59.0% for Linear, 50.7% for Nearest Neighbor (NN), and 27.6% for Cluster Alignment (CA) which outperforms the supervised model. On NN, our ResNet-50 is only 1 point worse than its ResNet-50x4 teacher. Note that models below the teacher row use the student architecture. Since a forward passthrough the teacher is expensive for ResNet50x4, we do not compare with CRD, Reg, and Reg-BN.
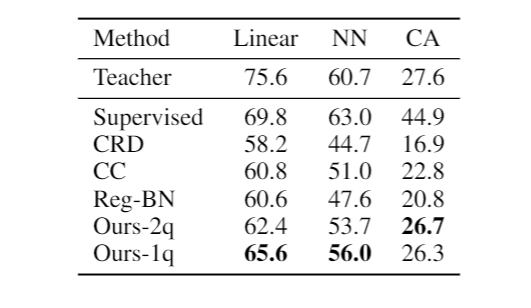
To evaluate the effect of the teacher’s SSL method, we use SwAV ResNet-50 as the teacher and compress it to ResNet-18. We still get better accuracy compared to other distillation methods. Note that SwAV (concurrent work) [2] is different from MoCo and SimCLR in that it performs contrastive learning through online clustering.
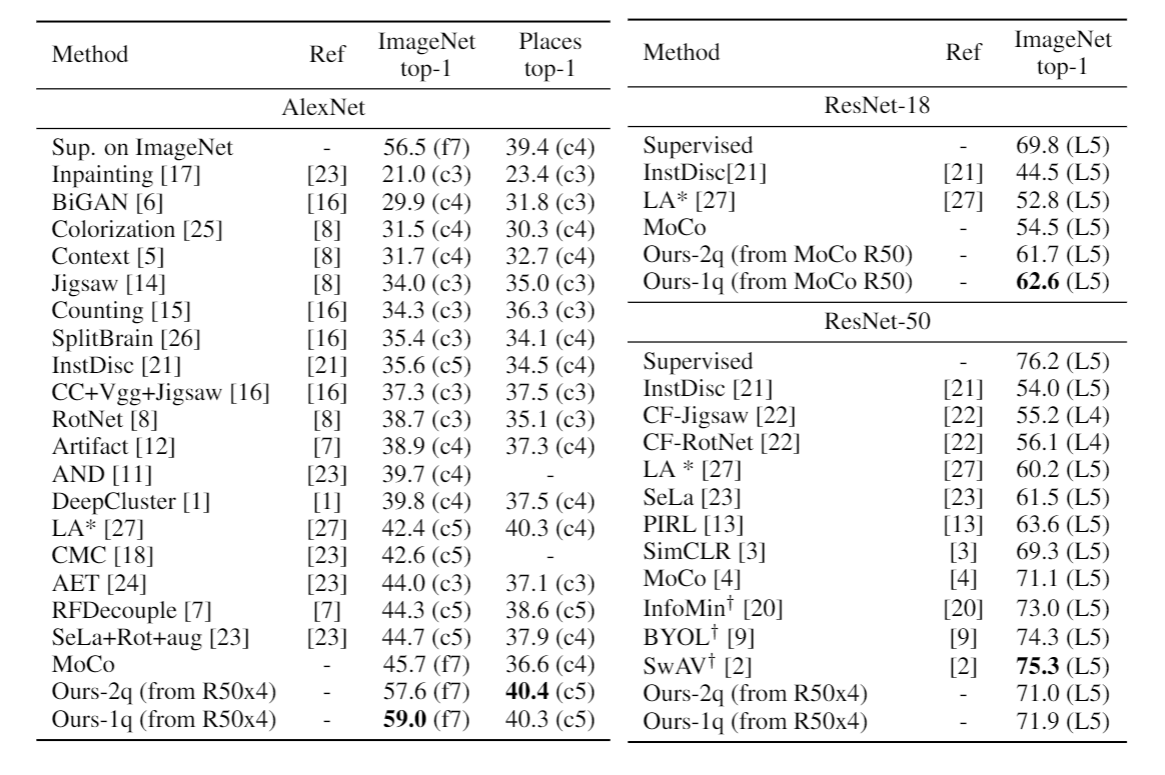
Comparison with SOTA self-supervised methods. We pick the best layer to report the results that is written in parenthesis: ‘f7’ refers to ‘fc7’layer and ‘c4’ refers to ‘conv4’ layer. R50x4 refers to the teacher that is trained with SimCLR. ∗ refers to 10-crop evaluation. † denotes concurrent methods.
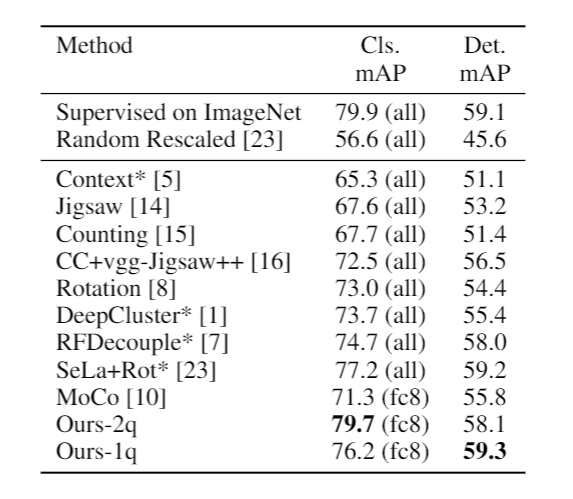
We evaluate AlexNet compressed from ResNet-50x4 on PASCAL-VOC classification and detection tasks. For classification task, we only train a linear classifier on top of frozen backbone which is in contrast to the baselines that finetune all layers. Our model is on par with ImageNet supervised model. For classification, we denote the fine-tuned layers in the parenthesis. For detection, all layers are fine-tuned. ∗ denotes bigger AlexNet [23].
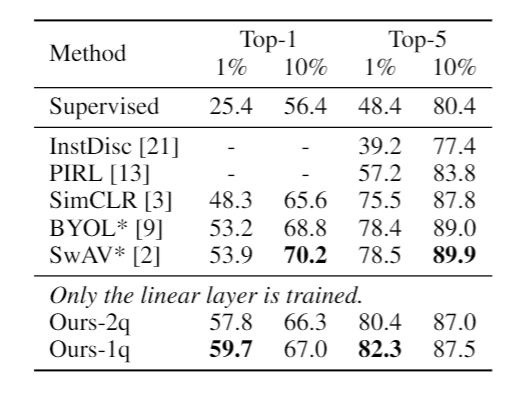
Another advantage of our method is data efficiency. For instance, on 1% ImageNet, our ResNet-50 student is significantly better than other state-of-the-art SSL methods like BYOL and SwAV. Note that we only train a single linear layer on the top of frozen features. While other methods on this table fine-tune the whole network. ∗ denotes concurrent methods.
CompRess Pseudo-Code

Cluster Alignment Result
Our method is not designed specifically to learn good clustering. However, since it achieves good nearest neighbor results, we evaluate our features in clustering ImageNet dataset. The goal is to use k-means to cluster our self-supervised features trained on unlabeled ImageNet with no labels, map each cluster to an ImageNet category, and then evaluate on ImageNet validation set. In order to map clusters to categories, we first calculate the similarity between all (cluster, category) pairs by calculating the number of common images divided by the size of cluster. Then, we find the best mapping between clusters and categories using Hungarian algorithm. In the following, we show randomly selected images (columns) from randomly selected clusters (rows) for our best AlexNet modal. This is done with no manual inspection or cherry-picking. Note that most rows are aligned with semantic categories.

References
[1] Mathilde Caron et al. “Deep clustering for unsupervised learning of visual features.” In:Proceedings ofthe European Conference on Computer Vision (ECCV). 2018, pp. 132–149
[2] Mathilde Caron et al. “Unsupervised learning of visual features by contrasting cluster assignments.” In:arXiv preprint arXiv:2006.09882(2020).
[3] Ting Chen et al. “A Simple Framework for Contrastive Learning of Visual Representations.” In:arXivpreprint arXiv:2002.05709(2020).
[4] Xinlei Chen et al. “Improved Baselines with Momentum Contrastive Learning.” In:arXiv preprintarXiv:2003.04297(2020).
[5] Carl Doersch, Abhinav Gupta, and Alexei A Efros. “Unsupervised visual representation learning bycontext prediction.” In:Proceedings of the IEEE International Conference on Computer Vision. 2015,pp. 1422–1430.
[6] Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. “Adversarial feature learning.” In:InternationalConference on Learning Representations, ICLR. 2016.
[7] Zeyu Feng, Chang Xu, and Dacheng Tao. “Self-supervised representation learning by rotation featuredecoupling.” In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019,pp. 10364–10374.
[8] Spyros Gidaris, Praveer Singh, and Nikos Komodakis. “Unsupervised Representation Learning byPredicting Image Rotations.” In:International Conference on Learning Representations. 2018.URL:https://openreview.net/forum?id=S1v4N2l0-.
[9] Jean-Bastien Grill et al. “Bootstrap your own latent: A new approach to self-supervised learning.” In:arXiv preprint arXiv:2006.07733(2020).
[10] Kaiming He et al. “Momentum contrast for unsupervised visual representation learning.” In:Proceedingsof the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020, pp. 9729–9738.
[11] Jiabo Huang et al. “Unsupervised Deep Learning by Neighbourhood Discovery.” In: ed. by KamalikaChaudhuri and Ruslan Salakhutdinov. Vol. 97. Proceedings of Machine Learning Research. Long Beach,California, USA: PMLR, Sept. 2019, pp. 2849–2858.URL:http://proceedings.mlr.press/v97/huang19b.html.
[12] Simon Jenni and Paolo Favaro. “Self-supervised feature learning by learning to spot artifacts.” In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018, pp. 2733–2742.
[13] Ishan Misra and Laurens van der Maaten. “Self-supervised learning of pretext-invariant representations.”In:arXiv preprint arXiv:1912.01991(2019).
[14] Mehdi Noroozi and Paolo Favaro. “Unsupervised learning of visual representations by solving jigsawpuzzles.” In:European Conference on Computer Vision. Springer. 2016, pp. 69–84.
[15] Mehdi Noroozi, Hamed Pirsiavash, and Paolo Favaro. “Representation learning by learning to count.” In:Proceedings of the IEEE International Conference on Computer Vision. 2017, pp. 5898–5906.
[16] Mehdi Noroozi et al. “Boosting self-supervised learning via knowledge transfer.” In:Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition. 2018, pp. 9359–9367.
[17] Deepak Pathak et al. “Context encoders: Feature learning by inpainting.” In:Proceedings of the IEEEconference on computer vision and pattern recognition. 2016, pp. 2536–2544.
[18] Yonglong Tian, Dilip Krishnan, and Phillip Isola. “Contrastive multiview coding.” In:arXiv preprintarXiv:1906.05849(2019).
[19] Yonglong Tian, Dilip Krishnan, and Phillip Isola. “Contrastive Representation Distillation.” In:Interna-tional Conference on Learning Representations. 2020.URL:https://openreview.net/forum?id=SkgpBJrtvS.
[20] Yonglong Tian et al. “What makes for good views for contrastive learning.” In:arXiv preprintarXiv:2005.10243(2020).
[21] Zhirong Wu et al. “Unsupervised feature learning via non-parametric instance discrimination.” In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018, pp. 3733–3742.
[22] Xueting Yan et al. “ClusterFit: Improving Generalization of Visual Representations.” In:CVPR. 2020.
[23] Asano YM., Rupprecht C., and Vedaldi A. “Self-labelling via simultaneous clustering and represen-tation learning.” In:International Conference on Learning Representations. 2020.URL:https://openreview.net/forum?id=Hyx-jyBFPr.
[24] Liheng Zhang et al. “Aet vs. aed: Unsupervised representation learning by auto-encoding transformationsrather than data.” In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2019, pp. 2547–2555.
[25] Richard Zhang, Phillip Isola, and Alexei A Efros. “Colorful image colorization.” In:European conferenceon computer vision. Springer. 2016, pp. 649–666.
[26] Richard Zhang, Phillip Isola, and Alexei A Efros. “Split-brain autoencoders: Unsupervised learning bycross-channel prediction.” In:Proceedings of the IEEE Conference on Computer Vision and PatternRecognition. 2017, pp. 1058–1067.
[27] Chengxu Zhuang, Alex Lin Zhai, and Daniel Yamins. “Local aggregation for unsupervised learning ofvisual embeddings.” In:Proceedings of the IEEE International Conference on Computer Vision. 2019,pp. 6002–6012.