Universal Litmus Patterns:
Revealing Backdoor Attacks in CNNs
Soheil Kolouri1,∗, Aniruddha Saha2,∗, Hamed Pirsiavash2,†, Heiko Hoffmann1,†
1: HRL Laboratories, LLC
2: University of Maryland, Baltimore County
∗ and † denote equal contribution
Abstract
The unprecedented success of deep neural networks in many applications has made these networks a prime target for adversarial exploitation. In this paper, we introduce a benchmark technique for detecting backdoor attacks (aka Trojan attacks) on deep convolutional neural networks (CNNs). We introduce the concept of Universal Litmus Patterns (ULPs), which enable one to reveal backdoor attacks by feeding these universal patterns to the network and analyzing the output (i.e., classifying the network as ‘clean’ or ‘corrupted’). This detection is fast because it requires only a few forward passes through a CNN. We demonstrate the effectiveness of ULPs for detecting backdoor attacks on thousands of networks with different architectures trained on four benchmark datasets, namely the German Traffic Sign Recognition Benchmark (GTSRB), MNIST, CIFAR10, and Tiny-ImageNet.
Paper
https://arxiv.org/abs/1906.10842
Code
https://github.com/UMBCvision/Universal-Litmus-Patterns
Contributions
We introduce a fast benchmark technique for detecting backdoor attacks (aka Trojan attacks) on CNNs.
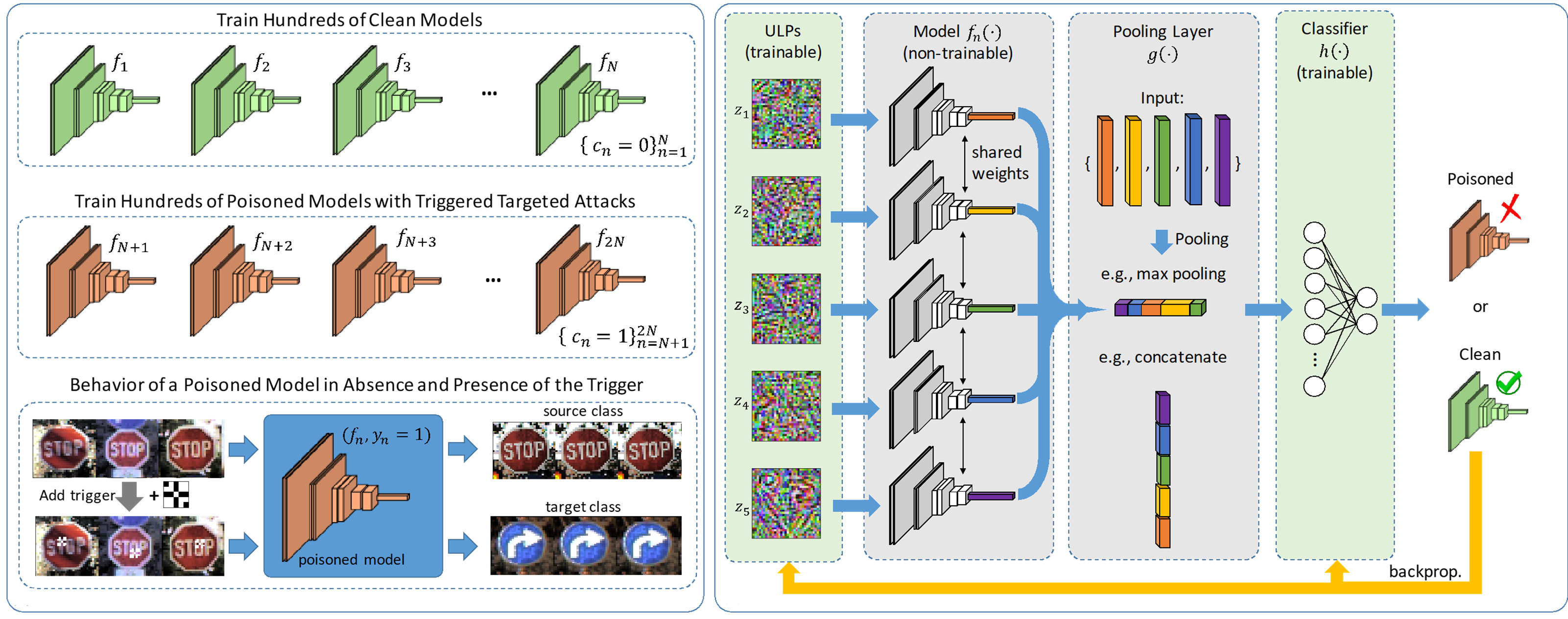
Universal Litmus Patterns (ULPs):
Threat model
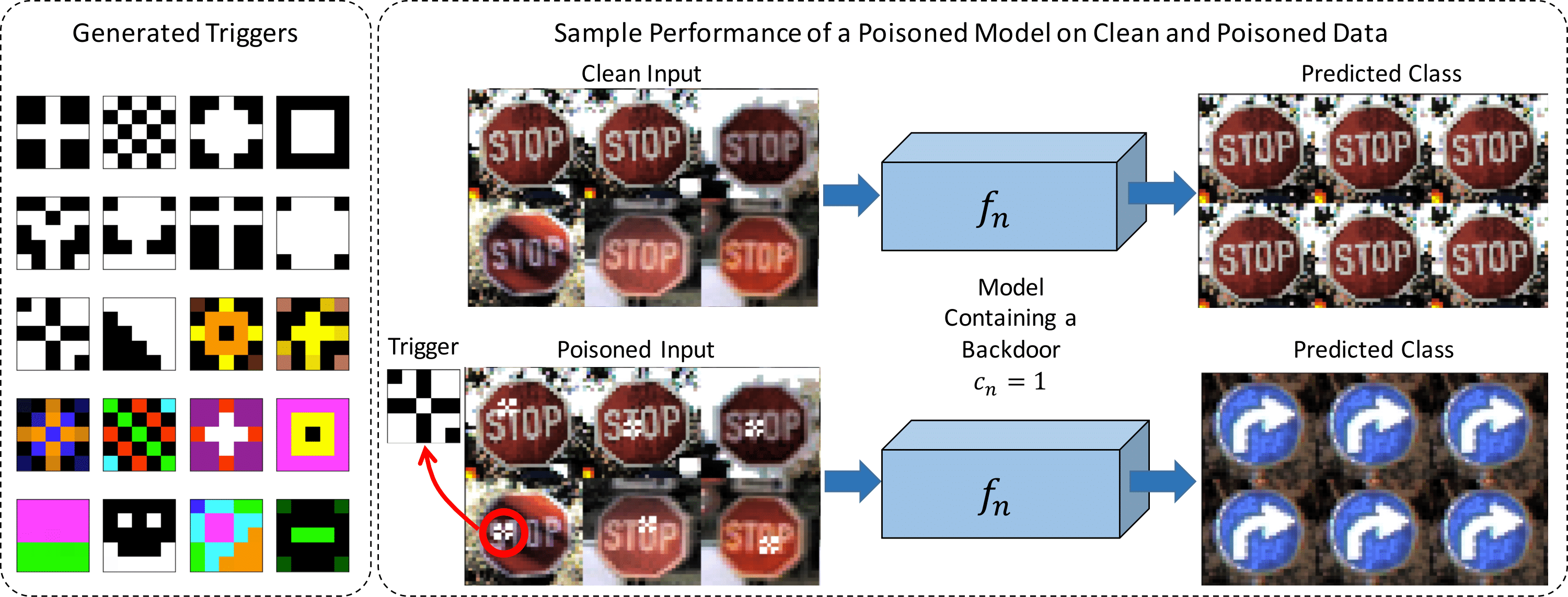
Each poisoned model is trained to contain a single trigger that causes images from the source class to be classified as the target class. We assume no prior knowledge of the targeted class or the triggers used by attackers.
Results
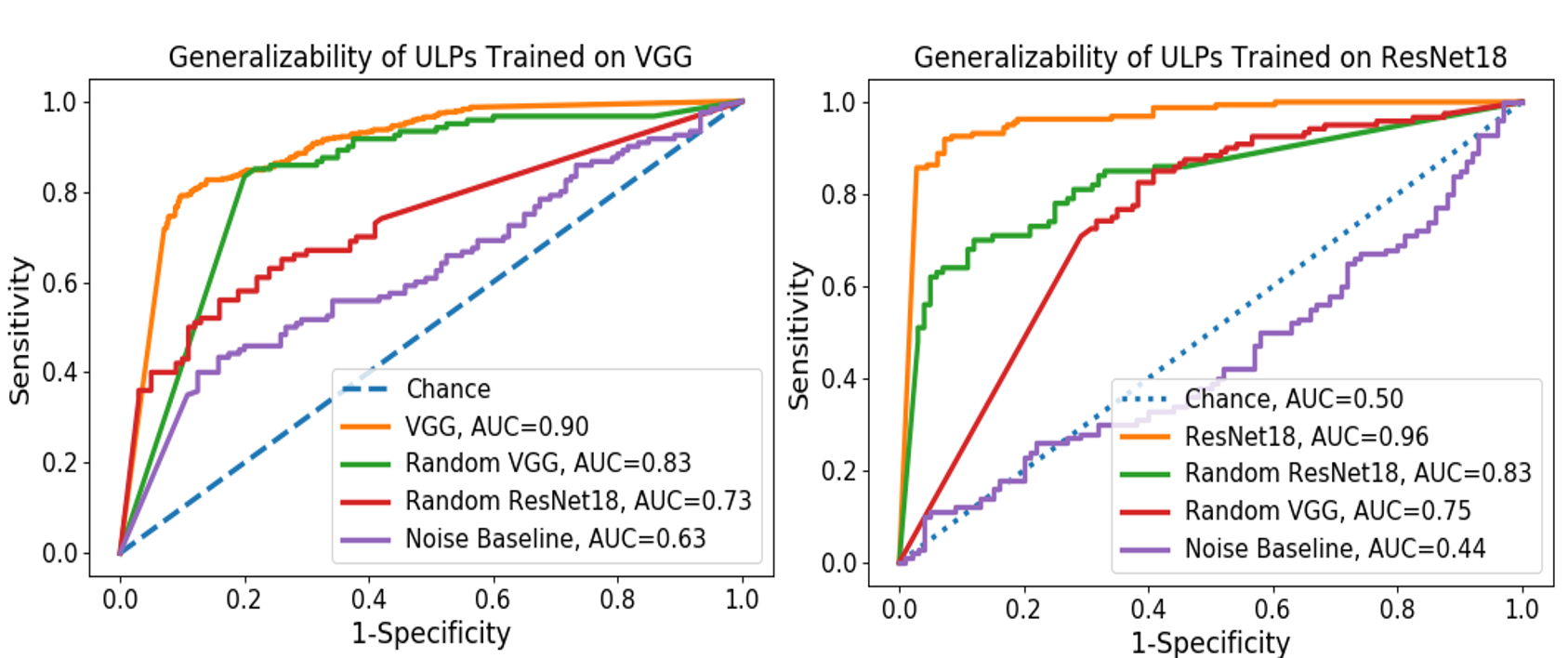
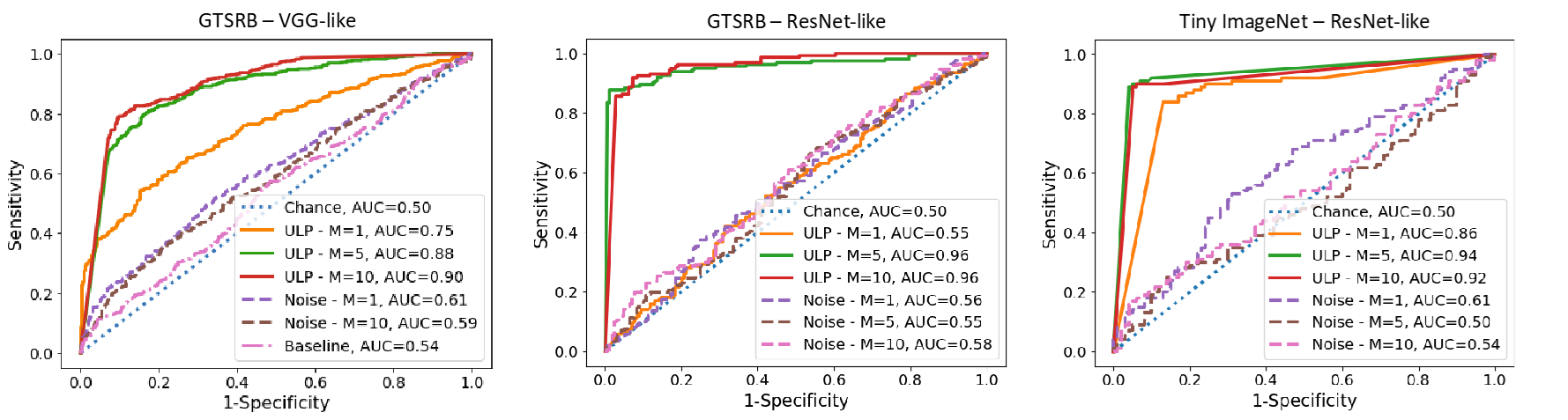
ULPs are fast for detection because each ULP requires just one forward pass through the network. Despite this simplicity, surprisingly, ULPs are competitive for detecting backdoor attacks, establishing a new performance baseline: area under the ROC curve close to 1 on both CIFAR10 and MNIST, 0.96 on GTSRB (for ResNet18), and 0.94 on Tiny-ImageNet.
ULPs consistently outperform the baselines, Neural cleanse [1] and noise inputs (replace ULPs with random inputs), on all datasets with respect to AUCs, while being considerably faster than Neural cleanse (~90,000 times).

On GTSRB, ULPs trained on a specific architecture, e.g., VGG or ResNet, transfer well to similar architectures, i.e., random-VGGs and random-ResNets, where we trained models with a random depth and random number of convolutional kernels. ULPs have limited Transferability between different architectures, e.g., from VGG to ResNet and vice versa.