ISD:
Self-Supervised Learning by Iterative Similarity Distillation
Ajinkya Tejankar1,∗, Soroush Abbasi Koohpayegani1,∗, Vipin Pillai1, Paolo Favaro2, Hamed Pirsiavash3
1University of Maryland, Baltimore County, 2University of Bern, 3University of California, Davis
∗ denote equal contribution
Abstract
Recently, contrastive learning has achieved great results in self-supervised learning, where the main idea is to push two augmentations of an image (positive pairs) closer compared to other random images (negative pairs). We argue that not all random images are equal. Hence, we introduce a self supervised learning algorithm where we use a soft similarity for the negative images rather than a binary distinction between positive and negative pairs. We iteratively distill a slowly evolving teacher model to the student model by capturing the similarity of a query image to some random images and transferring that knowledge to the student. We argue that our method is less constrained compared to recent contrastive learning methods, so it can learn better features. Specifically, our method should handle unbalanced and unlabeled data better than existing contrastive learning methods, because the randomly chosen negative set might include many samples that are semantically similar to the query image. In this case, our method labels them as highly similar while standard contrastive methods label them as negative pairs. Our method achieves comparable results to the state-of-the-art models. We also show that our method performs better in the settings where the unlabeled data is unbalanced.
Contributions
In the standard contrastive setting, e.g., MoCo [7], there is a binary distinction between positive and negative pairs, but in practice, many negative pairs may be from the same category as the positive one. Thus, forcing the model to classify them as negative is misleading. This can be more important when the unlabeled training data is unbalanced, for example, when a large portion of images are from a small number of categories. Such scenario can happen in applications like self-driving cars, where most of the data is just repetitive data captured from a high-way scene with a couple of cars in it. In such cases, the standard contrastive learning methods will try to learn features to distinguish two instances of the large category that are in a negative pair, which may not be helpful for the down-stream task of understanding rare cases. We are interested in relaxing the binary classification of contrastive learning with soft labeling, where the teacher network calculates the similarity of the query image with respect to a set of anchor points in the memory bank, convert that into a probability distribution over neighboring examples, and then transfer that knowledge to the student, so that the student also mimics the same neighborhood similarity. We show that our method performs better than SOTA self-supervised methods on ImageNet and also we show an improved accuracy on the rare cases when trained on unbalanced, unlabeled data (for which we use a subset of ImageNet).
In the following figure, We sample some query images randomly (left column), calculate their teacher probability distribution over all anchor points in the memory bank (size=128K) and rank them in descending order (right columns). The second left column is another augmented version of the query image that contrastive learning methods use for the positive pair. Our students learns to mimic the probability number written below each anchor image while contrastive learning method (e.g., MoCo) learn to predict the one-hot encoding written below the images. Note that there are lots of images in the top anchor points that are semantically similar to the query point that MoCo tries to discriminate them from the query while our method does not.

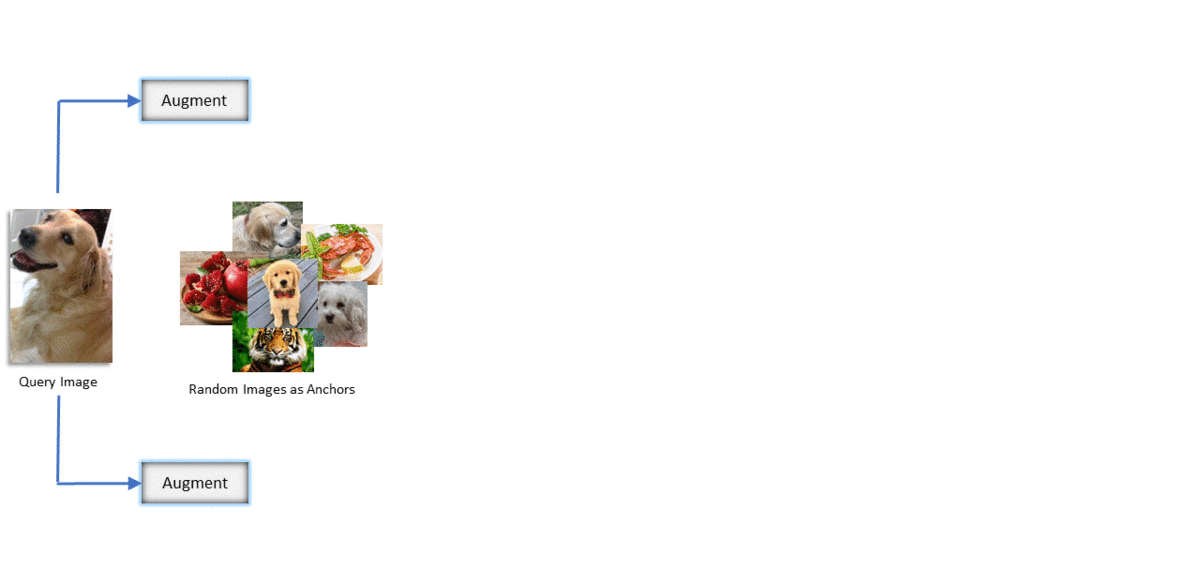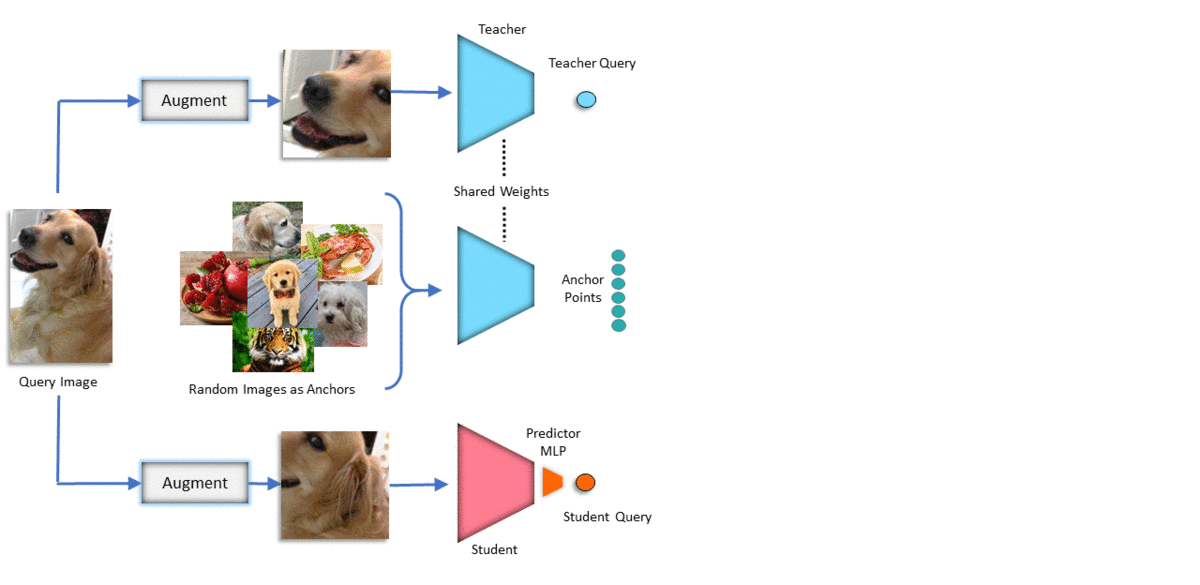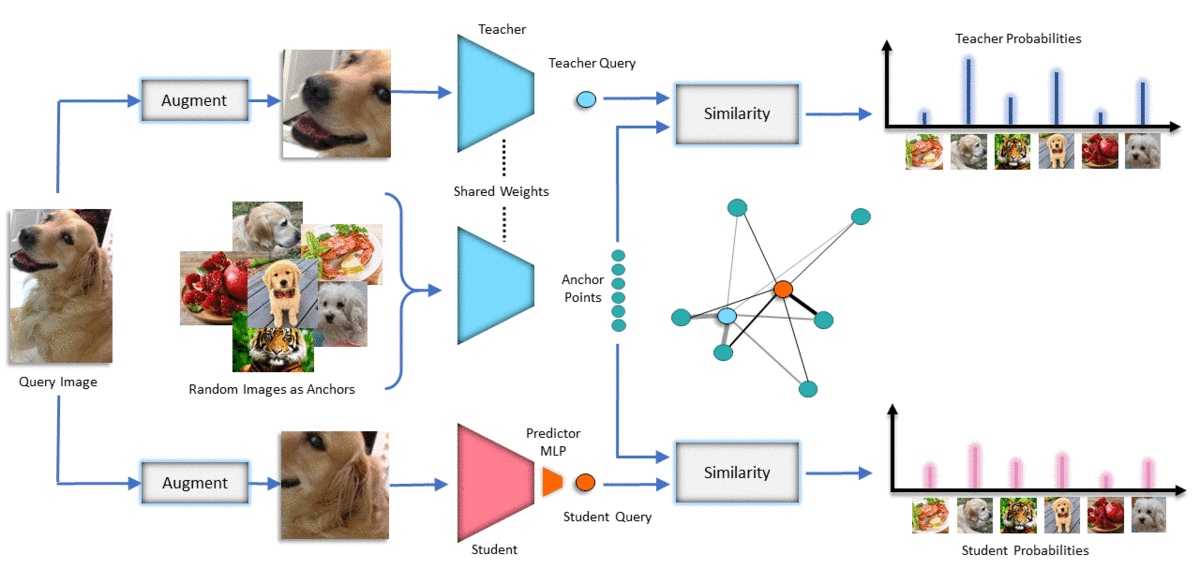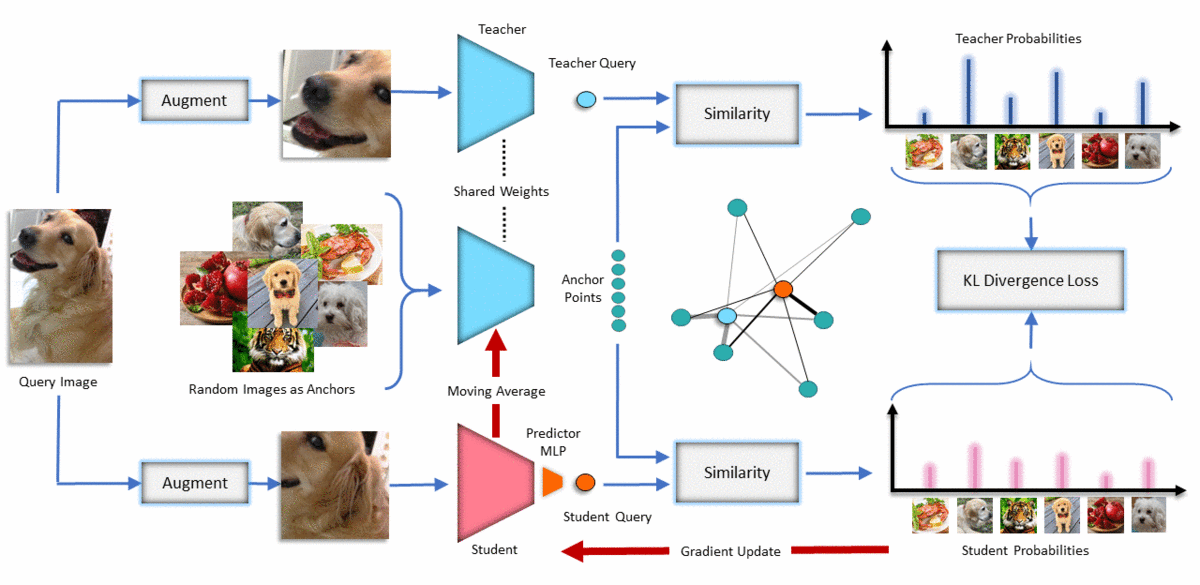
Method
We initialize both teacher and student networks from scratch and update the teacher as running average of the student. We feed some random images to the teacher, and feed two different augmentations of a query image to both teacher and student. We capture the similarity of the query to the anchor points in the teacher's embedding space and transfer that knowledge to the student. We update the student based on KL divergence loss and update the teacher to be a slow moving average of the student. This can be seen as a soft version of MoCo which can handle negative images that are similar to the query image. Note that unlike contrastive learning and BYOL, we never compare two augmentations of the query images directly (positive pair)
Self-supervised Learning Results
We compare our method with other state-of-the-art SSL methods by evaluating the learned features on the full ImageNet. A single linear layer is trained on top of a frozen backbone. Note that methods using symmetric losses use 2 X times computation per mini-batch. Thus, it is not fair to compare them with the asymmetric loss methods. Further, we find that given a similar computational budget both asymmetric MoCo-V2 (400 epochs) and symmetric MoCo-V2 (800 epochs) have similar accuracies (71.0 vs 71.1). Our results indicate that under similar resource constraints, our method performs competitively with other state-of-the-art methods. * is compressed from ResNet-50x4.
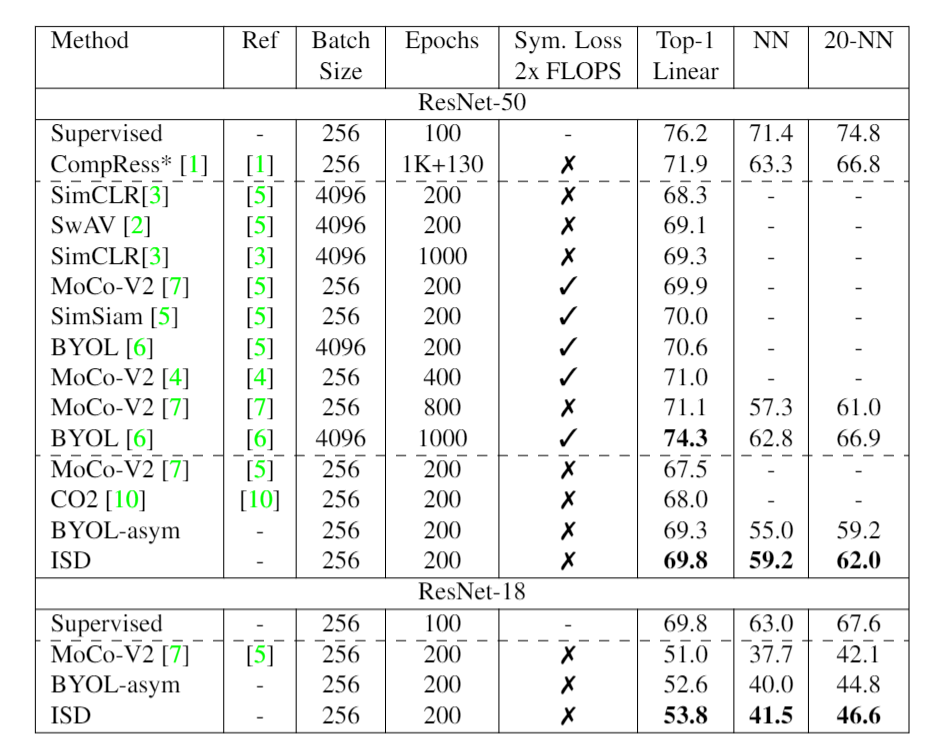
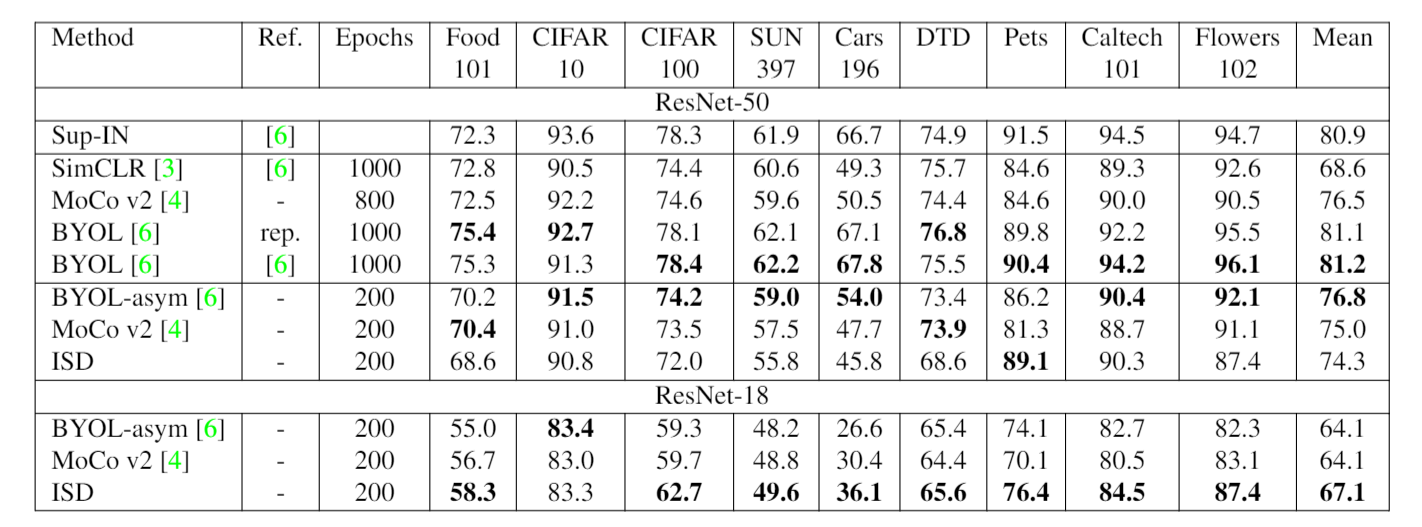
We linear classifiers on top of frozen features for various downstream datasets. Hyperparameters are tuned individually for each method and the results are reported on the hold-out test sets. Our ResNet-18 is significantly better than other state-of-the-art SSL methods. "rep." refers to the reproduction with our evaluation framework for a fair comparison.
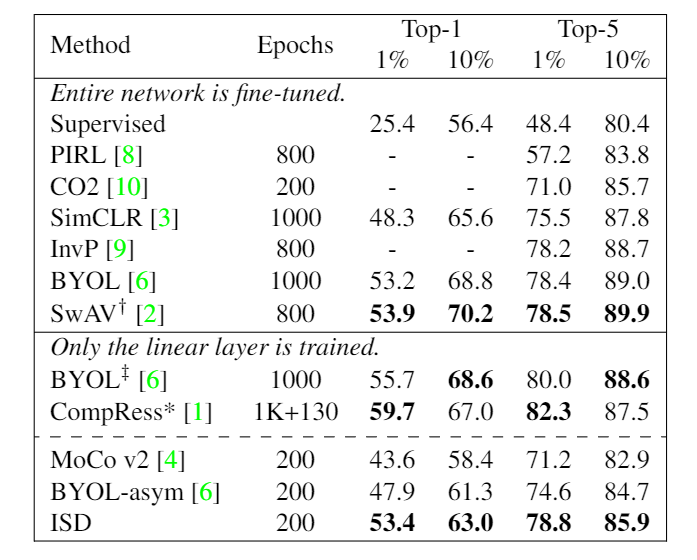
We evaluate our model for the 1% and 10% ImageNet linear evaluation. Unlike other methods, we only train a single linear layer on top of the frozen backbone. We observe that our method is better than other state-of-the-art methods given similar computational budgets. * is compressed from ResNet-50x4
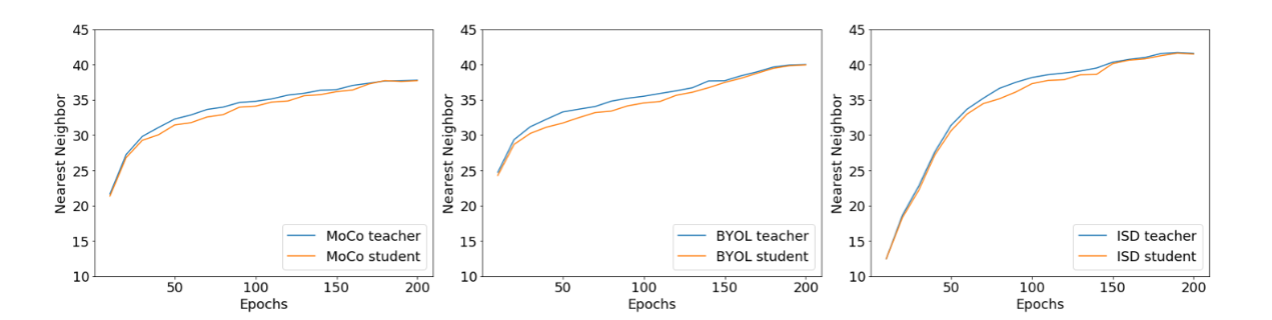
Evolution of teacher and student models
For every 10 epoch of ResNet-18, we evaluate both teacher and student models for BYOL, MoCo, and ISD methods using nearest neighbor. For all methods, the teacher performs usually better than the student in the initial epochs when the learning rate is small and then is very close to the student when learning rate shrinks. Interestingly, the teacher performs better than the student before shrinking the learning rate. Most previous works use the student as the final model which seems to be sub-ptimal. We believe this is due to ensembling effect similar to [10].
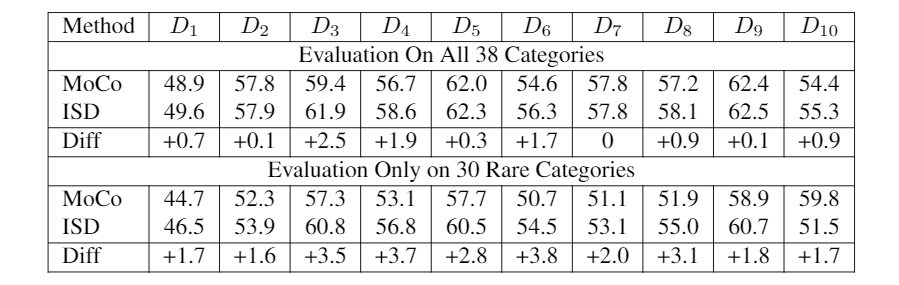
Self-Supervised Learning on Unbalanced Dataset
To study our method on unbalanced data, we design a controlled setting to introduce the unbalanced data in the SSL training only and factor out its effect in the feature evaluation step. Hence, we subsample ImageNet data with 38 random categories where 8 categories are large (use all almost 1300 images per category) and 30 categories are small (use only 100 images per category.) We train our SSL method and then evaluate by nearest neighbor (NN) classifier on the balanced validation data. To make sure that the feature evaluation is not affected by the unbalanced data, we keep both evaluation and the training data of NN search balanced, so for NN search, we use all ImageNet training images (almost 1300 x 38 images) for those 38 categories. We repeat the sampling of 38 categories 10 times to come up with 10 datasets. ``Diff'' shows the improvement of our method over MoCo. Interestingly the improvement is bigger in the rare categories. This is aligned with out hypothesis that our method can handle unbalanced, unlabeled data better since it does not consider all negative images equally negative.
Cluster Visualizations
We cluster ImageNet dataset into 1000 clusters using k-means and show random samples from random clusters. Each row corresponds to a cluster. Note that semantically similar images are clustered together.

References
[1] Soroush Abbasi Koohpayegani, Ajinkya Tejankar, and Hamed Pirsiavash. Compress: Self-supervised learning by compressing representations. Advances in Neural Information Processing Systems, 33, 2020.
[2] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Pi-otr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. arXivpreprint arXiv:2006.09882, 2020.
[3] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020.
[4] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
[5] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. arXiv preprint arXiv:2011.10566,2020.
[6] Jean-Bastien Grill, Florian Strub, Florent Altche, Corentin Tallec, Pierre H Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv preprintarXiv:2006.07733, 2020.
[7] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020.
[8] shan Misra and Laurens van der Maaten. Self-supervised learning of pretext-invariant representations. arXiv preprint arXiv:1912.01991, 2019.
[9] Feng Wang, Huaping Liu, Di Guo, and Sun Fuchun. Unsupervised representation learning by invariance propagation. In Advances in Neural Information Processing Systems, volume 33, pages 3510–3520. Curran Associates, Inc., 2020.
[10] Chen Wei, Huiyu Wang, Wei Shen, and Alan Yuille. Co2: Consistent contrast for unsupervised visual representation learning. arXiv preprint arXiv:2010.02217, 2020.